What most DBAs want is plan stability that is execution plans should only change when they will result in
performance gains. SQL plan management (SPM) ensures that runtime performance will never degrade due to the change of an execution plan. To guarantee this, only accepted (trusted) execution plans will be
used; any plan evolution will be tracked and evaluated at a later point in time and only be
accepted as verified if the new plan causes no runtime change or an improvement of the runtime.
The SQL Plan Management has three main components:
1. SQL plan baseline capture:
Create SQL plan baselines that represents accepted (trusted) execution plans
for all relevant SQL statements. The SQL plan baselines are stored in a plan
history in the SQL Management Base in the SYSAUX tablespace.
2. SQL plan baseline selection:
Ensure that only accepted execution plans are used for statements with a SQL
plan baseline and track all new execution plans in the plan history for a
statement.
The plan history consists of accepted and unaccepted plans. An
unaccepted plan can be unverified (newly found but not verified) or rejected
(verified but not found to performant).
3. SQL plan baseline evolution:
Evaluate all unverified execution plans for a given statement in the plan history
to become either accepted or rejected.
The SQL PLAN history enables the SPM aware optimizer to determine whether the
best-cost plan it has produced is a brand new plan
or not. A new plan represents a plan change that has potential to cause
performance regression. For this reason, the SPM aware optimizer does not choose
a brand new best-cost plan. Instead, it chooses from a set of accepted plans. An
accepted plan is one that has been either verified to not cause performance
regression or designated to have good performance. A set of accepted plans is
called a SQL plan baseline, which represents a subset of the plan history.
A brand new plan is added to the plan history as a non-accepted plan. Later, an
SPM utility verifies its performance, and keeps it as a non-accepted plan if it
will cause a performance regression, or changes it to an accepted plan if it
will provide a performance improvement. The plan performance verification
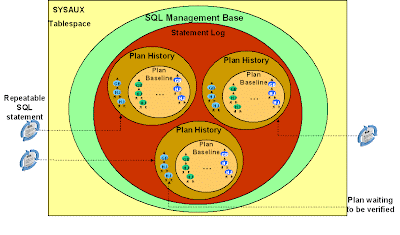
process ensures both plan stability and plan adaptability. The figure below shows the SMB containing the plan history for three SQL
statements. Each plan history contains some accepted plans (the SQL plan
baseline) and some non-accepted plans
1.SQL plan baseline capture:
You can create a SQL plan baseline in several ways: using a SQL Tuning Set
(STS); from the cursor cache; exporting from one database and importing into
another; and automatically for every statement. Let's look at each in turn.
Creating SQL plan baselines from STS
If you are upgrading from 10gR2 or
have an 11g test system, you might already have an STS containing some or all of
your SQL statements. This STS might contain plans that perform satisfactorily.
Let's call this STS MY_STS. You can create a SQL plan baseline from this STS as
follows:
SQL>
variable pls number;
SQL> exec :pls :=
dbms_spm.load_plans_from_sqlset(sqlset_name => 'MY_STS',
-
> basic_filter => 'sql_text like
''select%p.prod_name%''');
This will create SQL plan baselines for
all statements that match the specified filter.
Creating SQL plan baselines from cursor cache
You can automatically
create SQL plan baselines for any cursor that is currently in the cache as
follows:
SQL> exec :pls :=
dbms_spm.load_plans_from_cursor_cache( -
>
attribute_name => 'SQL_TEXT', -
> attribute_value
=> 'select%p.prod_name%');
This will create SQL plan baselines
for all statements whose text matches the specified string. Several overloaded
variations of this function allow you to filter on other cursor
attributes.
Creating SQL plan baselines using a staging table
If you already have
SQL plan baselines (say on an 11g test system), you can export them to another
system (a production system for instance). First, on the test system, create a
staging table and pack the SQL plan baselines you want to export:
SQL> exec
dbms_spm.create_stgtab_baseline(table_name => 'MY_STGTAB',
-
> table_owner => 'SH');
PL/SQL procedure
successfully completed.
SQL> exec :pls :=
dbms_spm.pack_stgtab_baseline( -
> table_name =>
'MY_STGTAB', -
> table_owner => 'SH',
-
> sql_text => 'select%p.prod_name%');
This will pack all SQL plan baselines for statements that match the specified
filter. The staging table, MY_STGTAB, is a regular table that you should export
to the production system using Datapump Export.
On the production system, you can now unpack the staging table to create the
SQL plan baselines:
SQL> exec :pls :=
dbms_spm.unpack_stgtab_baseline( -
> table_name =>
'MY_STGTAB', -
> table_owner => 'SH',
-
> sql_text => 'select%p.prod_name%');
This will unpack the staging table and create SQL plan baselines. Note that
the filter for unpacking the staging table is optional and may be different than
the one used during packing. This means that you can pack several SQL plan
baselines into a staging table and selectively unpack only a subset of them on
the target system.
Creating SQL plan from migrating stored outlines:
var mig clob
exec :mig:=dbms_spm.migrate_stored_outline(attribute_name=>-
> 'outline_name',attribute_value=>'OL1',fixed=>'NO')
Creating SQL plan baselines automatically
You can create SQL plan
baselines for all repeatable statements automatically by setting the parameter
optimizer_capture_sql_plan_baselines
to TRUE (default is FALSE). The first plan captured for any statement is
automatically accepted and becomes part of the SQL plan baseline, so enable this
parameter only when you are sure that the default plans are performing well.
You can use the automatic plan capture mode when you have upgraded from
a previous database version. Set optimizer_features_enable to the
earlier version and execute your workload. Every repeatable statement will have
its plan captured thus creating SQL plan baselines. You can reset
optimizer_features_enable to its
default value after you are sure that all statements in your workload have had a
chance to execute.
Note that this automatic plan capture occurs only for
repeatable statements, that is, statements that are executed at least twice.
Statements that are only executed once will not benefit from SQL plan baselines
since accepted plans are only used in subsequent hard parses.
The
following example shows a plan being captured automatically when the same
statement is executed twice:
SQL> alter session set
optimizer_capture_sql_plan_baselines = true;
Session altered.
SQL> var pid number
SQL> exec :pid :=
100;
PL/SQL procedure successfully completed.
SQL> select
p.prod_name, s.amount_sold, t.calendar_year
2 from sales s, products p,
times t
3 where s.prod_id = p.prod_id
4 and s.time_id =
t.time_id
5 and p.prod_id < :pid;
PROD_NAME AMOUNT_SOLD
CALENDAR_YEAR
--------- ----------- -------------
...
9 rows
selected.
SQL> /
PROD_NAME AMOUNT_SOLD CALENDAR_YEAR
---------
----------- -------------
...
9 rows selected.
SQL> alter
session set optimizer_capture_sql_plan_baselines = false;
Session
altered
Automatic plan capture
will not occur for a statement if a stored outline exists for it and is enabled
and the parameter use_stored_outlines is TRUE. In this
case, turn on incremental capture of plans into an STS using the function
capture_cursor_cache_sqlset() in the
DBMS_SQLTUNE package. After you
have collected the plans for your workload into the STS, manually create SQL
plan baselines using the method described earlier. Then, disable the stored
outlines or set
use_stored_outlines to FALSE. From now
on, SPM will manage your workload and stored outlines will not be used for those
statements. In this article, we have seen how to create SQL plan baselines. In
the next, we will describe the SPM aware optimizer and how it uses SQL plan
baselines.
2. SQL plan baseline selection:
Each time a SQL statement is compiled, the optimizer first uses the traditional cost-based search
method to build a best-cost plan. If the initialization parameter
OPTIMIZER_USE_SQL_PLAN_BASELINES is set to TRUE (default value) then before the cost
based plan is executed the optimizer will try to find a matching plan in the SQL statement’s SQL
plan baseline; this is done as in-memory operation, thus introducing no measurable overhead to
any application. If a match is found then it proceeds with this plan. Otherwise, if no match is
found, the newly generated plan will be added to the plan history; it will have to be verified
before it can be accepted as a SQL plan baseline. Instead of executing the newly generated plan
the optimizer will cost each of the accepted plans for the SQL statement and pick the one with
the lowest cost (note that a SQL plan baseline can have more than one verified/accepted plan for
a given statement). However, if a change in the system (such as a dropped index) causes all of the
accepted plans to become non-reproducible, the optimizer will use the newly generated costbased
plan.
It is also possible to influence the optimizer’s choice of plan when it is selecting a plan from a
SQL plan baseline. SQL plan baselines can be marked as fixed. Fixed SQL plan baselines indicate
to the optimizer that they are preferred. If the optimizer is costing SQL plan baselines and one of
the plans is fixed, the optimizer will only cost the fixed plan and go with that if it is reproducible.
If the fixed plan(s) are not reproducible the optimizer will go back and cost the remaining SQL
plan baselines and select the one with the lowest cost. Note that costing a plan is nowhere near
as expensive as a hard parse. The optimizer is not looking at all possible access methods but at
one specific access path.
3.SQL Plan Baseline Evolution
When the optimizer finds a new plan for a SQL statement, the plan is added to the plan history
as a non-accepted plan that needs to be verified before it can become an accepted plan. It is
possible to evolve a SQL statement’s execution plan using Oracle Enterprise Manager or by
running the command-line function DBMS_SPM.EVOLVE_SQL_PLAN_BASELINE. Using either of
these methods you have three choices:
1. Accept the plan only if it performs better than the existing SQL plan baseline
2. Accept the plan without doing performance verification
3. Run the performance comparison and generate a report without evolving the new plan.
If you choose option 1, it will trigger the new plan to be evaluated to see if it performs better
than a selected plan baseline. If it does, then the new plan will be added to the SQL plan baseline,
as an accepted plan. If not the new plan will remain in the plan history as a non-accepted plan
but its LAST_VERIFIED attribute will be updated with the current timestamp. A formatted text
report is returned by the function, which contains the actions performed by the function as well
as side-by-side display of performance statistics of the new plan and the original plan.
If you choose option 2, the new plan will be added to the SQL plan baseline as an accepted plan
without verifying its performance. The report will also be generated.
If you choose option 3 the new plan will be evaluated to see if it performs better than a selected
plan baseline but it will not be accepted automatically if it does. After the evaluation only the
report will be generated.
Monitoring SPM through DBA views
The view DBA_SQL_PLAN_BASELINES displays information about the SQL plan baselines
currently created for specific SQL statements. Here is an example.
select sql_handle, sql_text, plan_name, origin,
enabled, accepted, fixed, autopurge
from dba_sql_plan_baselines
The above select statement returns the following rows
SQL_HANDLE SQL_TEXT PLAN_NAME ORIGIN ENA ACC FIX AUT
-------- ---------- ------------- ------- --- --- --- ---
SYS_SQL_6fe2 select... SYS_SQL_PLAN_1ea AUTO-CAP YES NO NO YES
SYS_SQL_6fe2 select... SYS_SQL_PLAN_4be AUTO-CAP YES YES NO YES
…
In this example the same SQL statement has two plans, both of which were automatically captured. One of the plans (SYS_SQL_PLAN_4be) is a plan baseline as it is both enabled and accepted. The other plan (SYS_SQL_PLAN_1ea) is a non-accepted plan, which has been queued for evolution or verification. It has been automatically captured and queued for verification; its accepted value is set to NO. Neither of the plans is fixed and they are both eligible for automatic purge.
To check the detailed execution plan for any SQL plan baseline you can use the procedure
DBMS_XPLAN.DISPLAY_SQL_PLAN_BASELINE.
It is also possible to check whether a SQL statement is using a SQL plan baseline by looking in V$SQL. If the SQL statement is using a SQL plan baseline the plan_name for the plan selected from that SQL plan baseline will be in the sql_plan_baseline column of V$SQL. You can join the V$SQL view to the DBA_SQL_PLAN_BASELINES view using the following query:
Select s.sql_text, b.plan_name, b.origin, b.accepted
From dba_sql_plan_baselines b, v$sql s
Where s.exact_matching_signature = b.signature
And s.SQL_PLAN_BASELINE = b.plan_name;
Integration with Automatic SQL tuning
In Oracle Database 11g, the SQL Tuning Advisor, a part of the Tuning and Diagnostics pack, is
automatically run during the maintenance window. This automatic SQL tuning task targets highload
SQL statements. These statements are identified by the execution performance data
collected in the Automatic Workload Repository (AWR) snapshots. If the SQL Tuning Advisor
finds a better execution plan for a SQL statement it will recommend a SQL profile. Some of
these high-load SQL statements may already have SQL plan baselines created for them. If a SQL
profile recommendation made by the automatic SQL tuning task is implemented, the execution
plan found by the SQL Tuning Task will be added as an accepted SQL plan baseline.
The SQL Tuning Advisor can also be invoked manually, by creating a SQL Tuning Set for a
given SQL statement. If the SQL Tuning Advisor recommends a SQL profile for the statement
and it is manually implemented then that profile will be added as an accepted plan to the SQL
statements plan baseline if one exists.
Using SQL Plan Management for upgrade:
Undertaking a database upgrade is a daunting task for any DBA. Once the database has been
successfully upgraded you must still run the gauntlet of possible database behavior changes. On
the top of every DBA’s list of potential behavior changes are execution plan changes. With the
introduction of SQL Plan Management you now have an additional safety net to ensure
execution plans don’t change during the upgrade. In order to take full advantage of this safety net
you need to capture your existing execution plans before you upgrade so they can be used to seed
SPM.
Using SQL Tuning Sets:
If you have access to SQL Tuning Sets (STS) in the diagnostics pack then this is the easiest way
to capture your existing 10g execution plans. An STS is a database object that includes one or
more SQL statements along with their execution statistics, execution context and their current
execution plan. (An STS in Oracle Database 10gR1 will not capture the execution plans for the
SQL statements so it can’t be used to seed SPM. Only a 10gR2 STS will capture the plans).
To begin you will need to create a new STS. You can either do this through Oracle Enterprise
Manager (EM) or using the DBMS_SQLTUNE package. In this example we will use
DBMS_SQLTUNE.
BEGIN
SYS.DBMS_SQLTUNE.CREATE_SQLSET (
sqlset_name => 'SPM_STS',
description => '10g plans');
END;
\
Once the STS has been created we need to populate it. You can populate an STS from the
workload repository, another STS or from the cursor cache. In this case we will capture the SQL
statements and their execution plans from the cursor cache. This is a two-step process. In the
first step we create a ref cursor to select the specified SQL from the cursor cache (in this case all
non sys SQL statements). Then in the second step we use that ref cursor to populate the STS.
DECLARE
stscur dbms_sqltune.sqlset_cursor;
BEGIN
OPEN stscur FOR
SELECT VALUE(P)
FROM TABLE(dbms_sqltune.select_cursor_cache(
‘parsing_schema_name <> ‘‘SYS’’’,
null, null, null, null, 1, null, 'ALL')) P;
-- populate the sqlset
dbms_sqltune.load_sqlset(sqlset_name => 'SPM_STS',
populate_cursor => stscur);
END;
/
Once the software upgrade is completed the execution plans can be bulk loaded from an STS
into SPM using the PL/SQL procedure DBMS_SPM.LOAD_PLANS_FROM_SQLSET or
through Oracle Enterprise Manager (EM).
SQL> Variable cnt number
SQL> execute :cnt := DBMS_SPM.LOAD_PLANS_FROM_SQLSET( -
sqlset_name => 'SPM_STS');
Few bugs I noticed:
1. Packed sql tuning set in 10.2.0.5 and unpacked in 11.2.0.1. 11g DB was hanged when plan was enabled in 11g.
2. Sql plan baselines were packed and unpacked. When unpacked the one sqlplan baseline which had higher cost for same sql handle was not accepted in DB where it was unpacked. Later on that plan had to be evolved in order to be enabled.
Note: Optimizer_cost from view dba_sql_plan_baselines and actual cost as shown from dbms_xplan.display_sql_plan_baselines were different. It has reason to be so.
Reference: White paper SQL Plan Management in Oracle Database 11g
oracle blog 

